Like this article? Share it! Tweet
Lots of talk last week about the “smart grid” and “big data.”
The smart grid, or electricity network that uses digital communications technology to detect and react to local changes in usage, using computer-based remote control and automation. A large number of smart devices and sensors capture data points from the grid. Data is being collected from a variety of systems such as SCADA, Outage Management Systems (OMS), Smart Meters (AMI) etc.
Capturing data from this vast amount of equipment results in a lot of data points, generally referred to as ‘big data‘. Data is also recorded over time intervals allowing for trend analysis. So we have a high volume of data that is being captured at high velocity.
Traditionally this data was stored in RDMBS or SQL databases like Oracle but given the amounts of data this is quickly becoming a problem. With the volume of data, the cost of operations also increases. Scaling up requires DBA and/or IT involvement, extra licenses, extra storage all adding cost, just to name a few. Getting all that (streaming) data in and into a digestible format is another challenge.
To solve these problems, several [newer] types of databases have become popular, sometimes referred to as NoSQL databases. Examples are MongoDB (good with JSON data formats) or Bigtable (good for analyzing large datasets using Map/Reduce techniques) as well as many others. While this solves some of the problems of scaling and storage, the fact that different devices yield different pieces of information is still a problem. To analyze this data, special (custom) software needs to be written to combine and query the data. This dramatically increases cost (we know, we’re software developers) and the time it takes to make changes takes a lot of effort. Effort that should be spent on business analysis, in our opinion. After all, the goal is not to build the system, the goal is to analyze data to meet the clients business needs.
Several solutions have been proposed such as standardizing data formats and protocols. But the bigger picture is that we’re not only talking about SCADA, OMS’s and Smart Meters, data could be anything: customer data, weather information, wildlife data, photos from field inspections, public data (FEMA, Census) etc. We, at Cliffhanger Solutions, think there is an even better solution: a search engine.
The big guys like Google and Microsoft don’t use RDBMS or NoSQL. These systems (extremely simplified) are based on the concept of an index to find data fast. To the contrary, search engines use a reversed index.
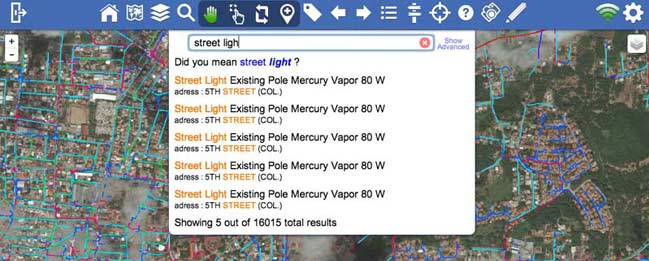
This is exactly what we built, a search engine or more specifically a real time spatial search engine. A spatial search engine is a search engine optimized for finding geo spatial data. And let’s face it, most data has a spatial component: customers have an address, sensors have a location, even photos have lat/long metadata these days. Once operational, the search engine can index data from any kind of enterprise system using a spider (a.k.a robot or crawler). The format of the data becomes less important. For example imagine a simplified example where we have a GIS database with distribution pole data and a field called ‘material’ and we have another dataset (like an EMS) with transmission poles with a field called ‘material type’. In a traditional SQL database you have to write a query on both tables and then join the results. In a search engine you can just search for ‘steel’ and not only will it find data from both pole datasets, but possibly from other sources that you weren’t even aware of. This puts a lot of power in the hands of the data analyst instead of the software developers, DBA’s etc. In other words, you can focus on your core business. This also means you don’t need to know all your questions in advance, you can start ‘browsing’ your data and explore. Additionally it is extremely easy to add new datasets. As new smart devices start flowing data, this new data can easily be explored without large efforts customizing existing applications, which would make them complex and inflexible.
At Distributech several people stopped by with questions like:
We have x TB of data and growing, but we’re pretty small so can’t afford large and expensive [analytics] systems. Can you help us?
Wow. Fortunately for them (and for us) the answer was yes. We’ve worked in the utility industry for over 2 decades, with many of them small(er) clients and this is exactly why we built what we built: to help utilities improve their operations without breaking the bank.
But it doesn’t stop there. In addition to the “find my stuff and make sense of it” our search engine, Atlas, allows you to find data using natural language, just like Google or Bing, after all, it is a search engine. This allows you to run sophisticated ‘queries’ like:
Find all circuits with a current outage in region x sorted by customer density.
And in the end, that’s what it is all about: improving customer service, keeping the lights on and saving cost.
To conclude, the big takeaway is that big data is here, but it’s overwhelming and complicated to make sense of it, but as we’ve shown it doesn’t have to be.