In the context of this article, concurrent users refers to the ability for a system to process requests from 2 or more users within a defined period of time. And this brings me immediately to the point: “within a defined period of time”. What time period? 1 day, 1 minute, 1 ms?
Vendors typically sell their licenses based on the concept of concurrent users or named users. The concept of named users is very clear: every possible user requires a license. However, the concept of concurrent users creates a challenge: If a company has a 100 users, not all users might be equally active. There might be a small core group of heavy users, say 20, and the other 60 are occasional users, and 20 might do the night shift. So you need anywhere between 20 and 80 licenses, because during peak day hours there might be 80 users. So to be safe, a license for 80 concurrent users is purchased. Alternatively, to save money, only 50 concurrent licenses might be purchased. This covers most of the daily operations but at certain peak hours some users will not be able to obtain access.
When vendors specify concurrency in their license terms, they usually do not mention the associated time period during which a license remains locked. It is assumed the number of users “logged in”. But what does that mean? A user that is logged in is not necessarily active. It is a scheme by vendors to extract more dollars from their clients. We, at Cliffhanger Solutions, think this is wrong, and this is how we do concurrency, or rather how we don’t do concurrency:
Take a look at the following chart. It shows the number of [API] requests (count) over time. Each bar represents 12 hours. We can see a peak load on the left of 38000 requests. This translates to 3166 requests per hour or 880ms between requests. Since the average of API calls (on this server) is around 42ms the server load is well within range. Right? Wrong.
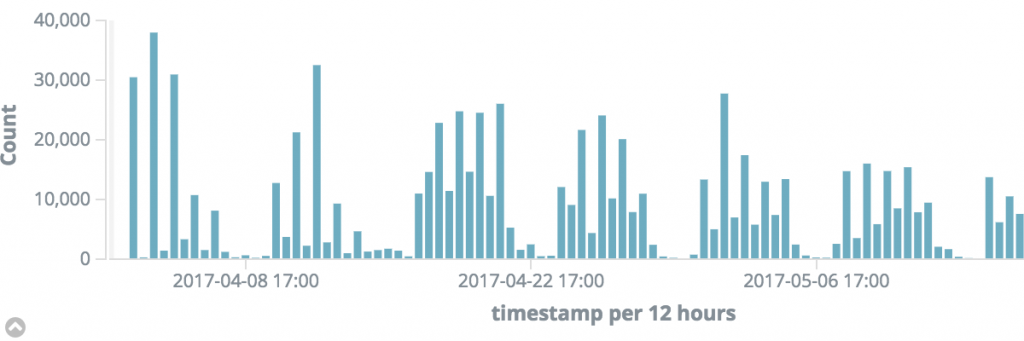
What if all of the 38000 requests occur within 1 hour of the 12 hour period? This translates to 10 requests per second or 100ms. So in order to get a better estimate we need to zoom in more:
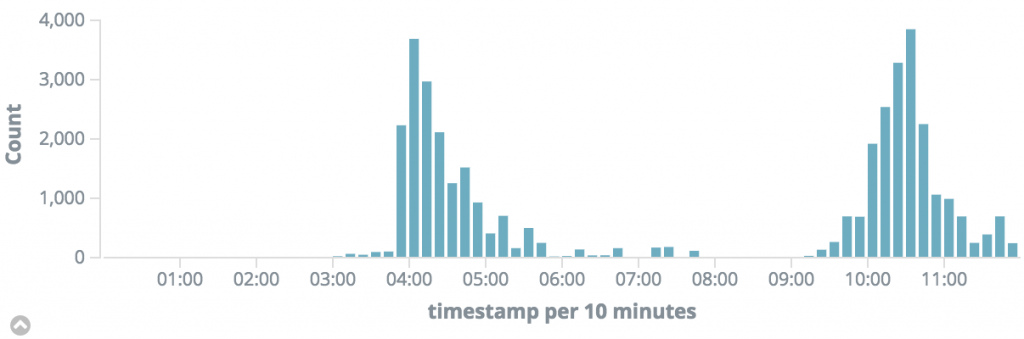
As you can see, the load is not evenly spread out over time but occurs in 2 bursts. Let’s zoom in more:
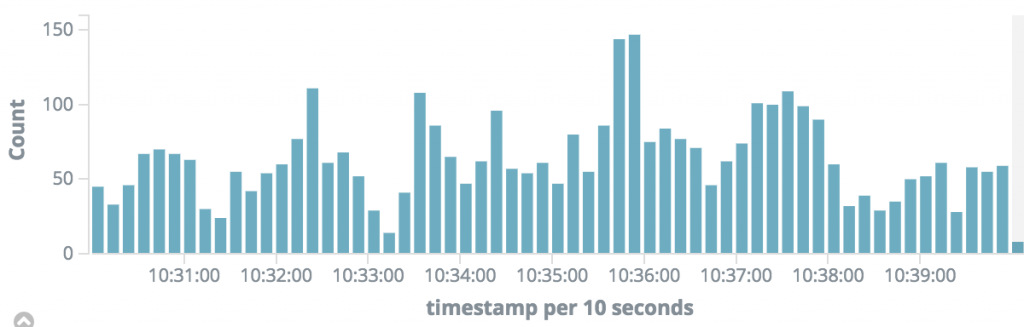
And finally some more:
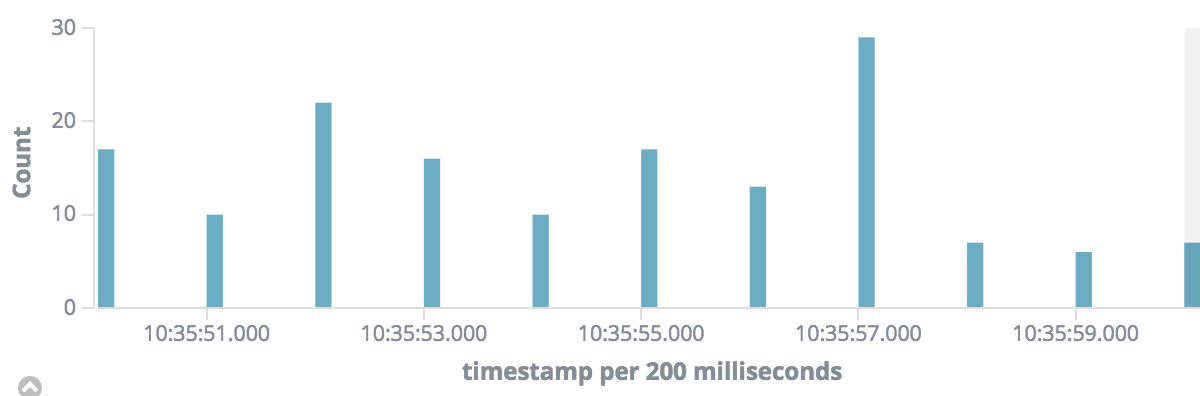
We see a peak of 30 API calls per 200ms, or 6.6ms on average per API call is available, well below the average of 42ms that is needed. So what happens is that during these peak periods, on this particular server, users will experience a delayed response. As long as the delay says below the timeout period (which we’ve set to 10s) users will be able to function.
We, at Cliffhanger, determine the amount of “concurrent users” based on server load, which is a much fairer approach. As a result we will never lock users out.
The charts in this article are available in real time on our dashboards. Client supervisors also have access to these metrics. So well before we reach the point of server overload, we can recommend scaling up, by upgrading the server or add additional servers to the load balancer. This way, clients always experience optimal performance at the best cost, with full transparency.